
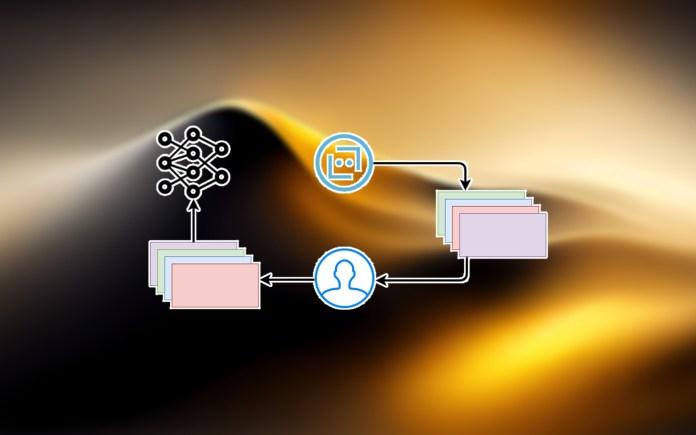
The methodology of RLHF
-
RLHF optimizes machine learning models using human feedback to align artificial intelligence with human preferences.
Reinforcement Learning from Human Feedback (RLHF) is an innovative approach that refines machine learning models by actively incorporating feedback from humans. In RLHF, human evaluators provide insights that guide the model’s learning process, allowing it to better adapt to human preferences and societal norms. This feedback loop aligns AI behavior with desired outcomes that cannot be easily captured through traditional data sets and algorithms. By interpreting feedback on the quality, relevance, and appropriateness of responses, AI can be tailored more accurately to reflect human values, enhancing its utility and acceptance in diverse applications. This methodology is particularly valuable in scenarios where objective benchmarks are insufficient, ensuring that AI outputs resonate more closely with human intent and expectations.
-
The reward model in RLHF is trained using human feedback to predict if a response to a given prompt is good or bad by ranking data collected from human annotators.
In Reinforcement Learning from Human Feedback (RLHF), the reward model plays a crucial role by using human feedback to evaluate responses to prompts. This is achieved through a process where human annotators provide rankings or evaluations based on personal judgment, which the model leverages to discern favorable from unfavorable responses. The model learns to interpret these rankings to predict the quality of future responses, ultimately guiding the AI’s decision-making process. By integrating diverse human perspectives, this approach helps align model outputs with human preferences, ensuring more accurate and contextually relevant responses in various applications.
- RLHF integrates human feedback within the reward function to train software to make decisions more aligned with human desires.
- The methodology is especially suitable for tasks where explicitly defining a reward function that aligns with human preferences is challenging.
- Human feedback trained models have been pivotal in AI successes, providing crucial alignment with human values on subjective goals.
Applications of RLHF
- RLHF is used in natural language processing tasks like text summarization and conversational agents.
- Computer vision tasks, including text-to-image models and video game bots, benefit from RLHF methodologies.
- State-of-the-art large language models are regularly trained using RLHF to improve outputs in terms of accuracy and adherence to instructions.
- RLHF facilitates the development of more engaging and human-like chatbot responses compared to conventional methods.
- RLHF’s application extends to AI image and music generation, affecting realism and mood perception.
Challenges with RLHF
- Ensuring high-quality preference data is essential but can be an expensive process.
- RLHF risks include potential biases arising from non-representative human feedback samples.
- Human feedback is subjective and can introduce disagreements and noisy feedback affecting model performance.
- Despite being resource-intensive, RLHF proves costly in gathering firsthand human input needed for feedback processes.
Future outlook of RLHF
-
Advancements in RLHF are leading the way in developing AI systems that mimic human behaviors and decision-making processes more closely than ever.
Recent advancements in Reinforcement Learning from Human Feedback (RLHF) have significantly enhanced the capability of AI systems to emulate human-like behaviors and decision-making processes. By leveraging nuanced human feedback, RLHF allows AI to learn subtle preferences and complex decision patterns that are difficult to code explicitly. This has enabled AI to process information closer to the way humans do, accounting for context and subjective elements that traditional methods might overlook. As a result, AI models equipped with RLHF can make decisions that reflect a deeper understanding of human values and expectations, fostering trust and facilitating more natural human-machine interactions. Consequently, these AI systems become more adept at addressing nuanced scenarios, offering personalized and contextually relevant responses.
- The adaptability of RLHF allows for its application in aligning AI models across diverse generative AI applications.
- Future RLHF methodologies may incorporate reinforcement learning from AI feedback, reducing costs associated with human feedback.
- The field remains at the forefront of addressing ethical considerations and enhancing AI’s contextual understanding.
♠
What are your thoughts on this tool? Leave feedback →




